
|
|
|
For this project we implemented the core routines of a physically-based renderer that uses a path-tracing algorithm. The first of these core routines was ray-scene intersection, which allowed us to calculate intersection points between camera rays and objects in the scene. The second was acceleration structures, such as the bounding volume hierarchy which minimized the number of ray intersections we had to compute, speeding up rendering time significantly. The third and fourth were direct and global illumination calculations, using Monte Carlo integration and various sampling methods, for more realistic lighting. The last was adaptive sampling which optimized the number of samples taken per pixel by checking for convergence.
A physically-based renderer relies on the physical model of light which describes light as rays that travel in straight lines from light sources (such as light fixtures or the sun), bouncing off of objects in the world into our camera lens. Modeling scenes in this way allows us to get very realistic renderings of images. However, computing lighting calculations for every conceivable ray in our scene and figuring out which ones reflect back into our imaginary camera would be impossible to properly and efficiently implement.
To solve this, we can model light as a ray (
To do this we can take points from each pixel in image space (The coordinate system for the image) and project them into camera space (The
coordinate system for the camera) using a series of translations and scales. If we multiply this point in camera space by
the camera-to-world rotation matrix we can project the camera space point (the point we shoot the ray through from the camera
origin) out into world space (The coordinate system the whole scene uses). From here we can test the camera ray for intersection
with objects that are situated in the scene. This is achieved by solving for intersection points using the ray equation
(
In order to test a ray for intersection with a triangle we used the Möller Trumbore algorithm, as shown below:

|
This allows us to express the plane intersection point of a ray as a set of barycentric coordinates for the triangle
(

|

|
|
|

|
Our recursive BVH construction algorithm takes a set of primitives from the scene and initializes a

|

|

|

|

|
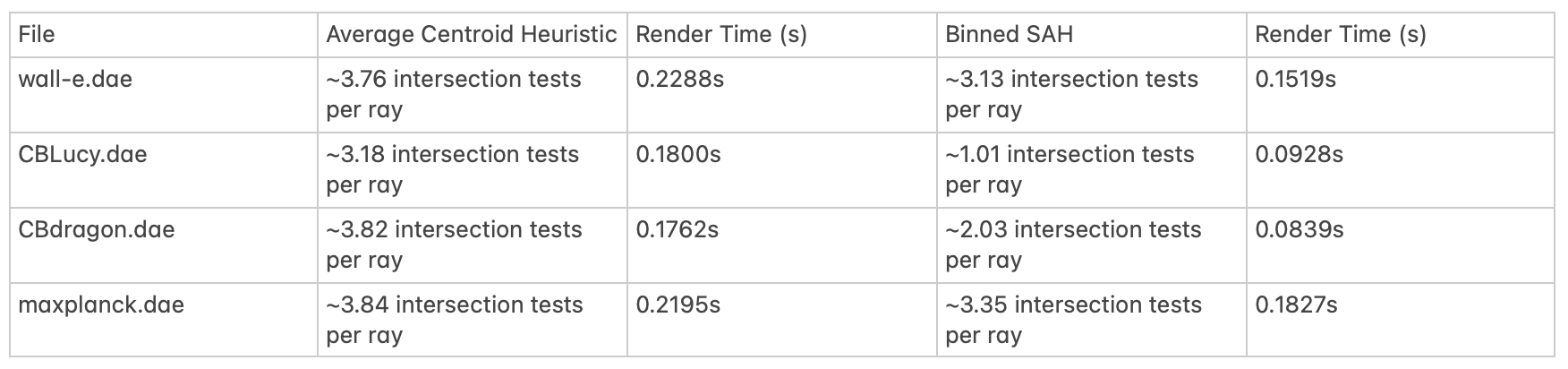
After implementing the Bounding Volume Hierarchy (BVH) we were able to render scenes significantly faster than when we were rendering
them with the naive method of exhaustively testing for ray intersections with every single primitive. For example, without the BVH cow.dae
took 301.57s to completely render (~5 minutes). With the BVH, it took only 0.1363s to fully render. Larger files like CBLucy.dae were practically
impossible to render on our local machines without the BVH. Partitioning the primitives into a hierarchical tree structure of
bounding boxes allows us to efficiently traverse the spatial area of the scene in order to find the small set of primitives actually intersected by
a particular ray in logarithmic time. This is because we can ignore entire collections of primitives if the ray of interest does not intersect
with the bounding box of a
In order to more optimally partition nodes in the BVH we utilized a binned surface area heuristic during BVH construction. Essentially, we split each
node's bounding box into
With this new heuristic we made marginal improvements to rendering speed, but were still able to reduce the number of intersection tests per ray. This reduction is more significant for files where there is a more uneven distribution of primitives (i.e. odd geometry, more protrusions, etc...) like CBLucy.dae where there is more to be gained from making smart partitions as we can reduce the amount of empty space included in the bounding boxes of nodes, letting us ignore nodes which we would have otherwise had to explore if we used a worse heuristic (i.e. Nodes we need to check in situations where the ray intersects the bounding box, but still misses all of the primitives contained within).
|
For Uniform Hemisphere Sampling, we first get a direction vector uniformly at random from the hemisphere coordinate system for the hit point. We take that vector and change it to the world's coordinate system and create a ray that can be tested for intersection against the bounding volume hierarchy. If it intersects, we get the emission of the intersected object, the BSDF of the hit point, and the cosine angle of the hemisphere sample. We multiply these together and add these according to the Monte Carlo estimator and repeat this process until we have the desired number of samples. After all the samples have been taken, we can account for the constant PDF (2π) by multiplying by the PDF and then we return the result divided by the number of samples taken.
For Light Importance Sampling, we go through every light in the scene. Point lights are sampled once whereas area lights are sampled
| Uniform Hemisphere Sampling | Light Sampling |
|---|---|

|

|

|

|

|

|

|

|
The changing number of light rays changes the number of samples we take of area lights. At lower counts, each point in space has noisier
radiance due to the fact that if that spot samples an area of the light that isn't blocked and its neighbor samples a different area of the
light that is blocked or has a different value for
The hemisphere sampling is noticeably more noisy than the light sampling due to the random nature of the sampling that can make the radiance vary wildly due to the randomness of where the ray lands. The only light in both scenes is the ceiling light so every spot's brightness will vary vastly from neighboring areas if it samples more of the light with its limited number of random samples. Light sampling only samples the lights for each spot instead of sampling random directions. Specifically, it samples different areas of the light. The noise seems to take form as spots being darker than they should be, which is why in the light sampling images, he scene as a whole seems brighter. The light also doesn't "bleed" through the edges in the light sampled images.
In order to implement indirect lighting we recursively bounced rays off of intersected surfaces. This lets us more accurately simulate the behavior of light rays which are reflected off of both illuminated and shadowed surfaces many times (rather than only from areas that are directly illuminated) before entering the camera. Thus, the gobal radiance reflected back into the camera is the accumulation of radiance measured at all of the reflected hit points of the inverse camera ray.
The bulk of our indirect lighting algorithm lies in the function

|

|

|

|
In the figure above, we see CBbunny.dae rendered once with only direct lighting, and once again with only indirect lighting.

|

|

|

|
|
|
In the series of images above, we can see that increasing the ray depth increases the overall brightness of the image. Note that at ray depth = 0, the scene is rendered with only the zero bounce radiance. Similarly, at ray depth = 1, the scene is rendered with only direct lighting. At ray depths greater than one, indirect lighting is included.

|

|

|

|

|

|

|
In the above series of images above, we can see that increasing the sample rate decreases the amount of noise in the image.
As shown above, in order to decrease the amount of noise in our renders we simply need to increase the sample rate. However,
sampling at a fixedly high rate for every single pixel is not cost efficient, as some pixels converge earlier than others. Adaptive
sampling solves this issue by letting us concentrate the samples on the most complicated parts of the image. To implement this we check
for convergence every 32 samples using the convergence variable
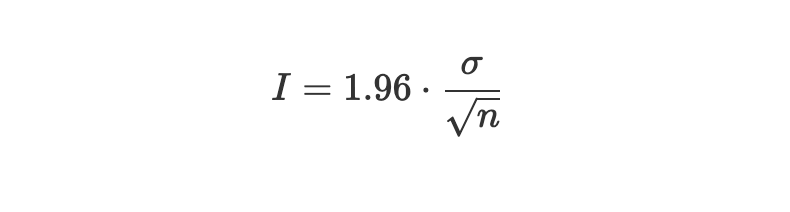
|
In this case
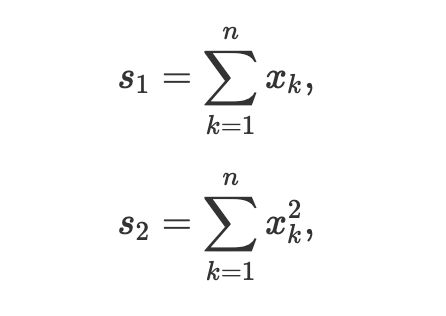
|
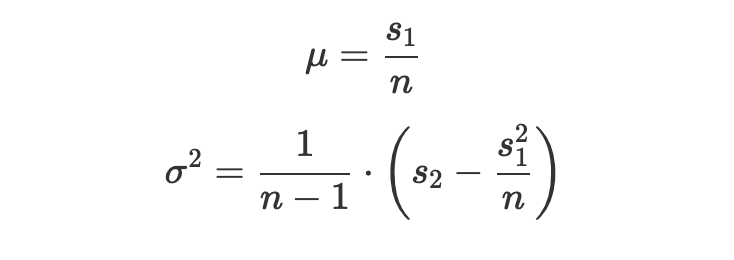
|
By updating
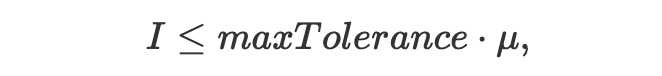
|
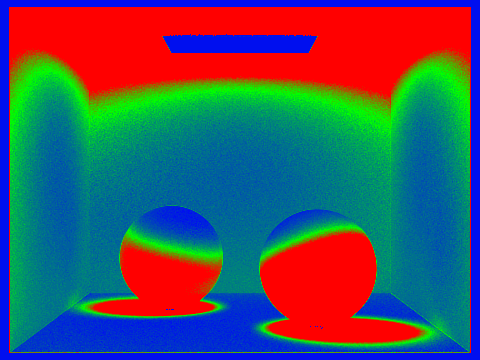
Once we've confirmed that a pixel has converged we stop sampling. Below are scenes that have been rendered with adaptive sampling. For
these images we use a

|
|

|

|